the medallion architecture is not an architecture
if you’ve worked in the databricks ecosystem for more than five minutes, someone has told you about the medallion architecture. bronze, silver, gold. raw, cleaned, aggregated. it’s in the docs, the sales decks, the onboarding material, and every medium article written by someone who just finished a databricks certification.
“a data design pattern used to logically organize data in a lakehouse, with the goal of incrementally and progressively improving the structure and quality of data as it flows through each layer.”
they recommend it as the default organizational pattern for every lakehouse implementation they sell.
daniel beach called it a “farce” and traced the term to a june 2020 databricks blog post where they deliberately wrote “OUR medallion architecture.” joe reis, in fundamentals of data engineering, wrote the medallion architecture is “no more a data model than a parking lot is a type of car.”
most of these critiques focus on the naming, or the redundancy, or the storage costs. that’s all valid. i think they stop short of the real question: why does the bronze layer exist at all? the answer has nothing to do with data quality best practices. it has everything to do with how spark processes data.
the point of this post is to show it’s not architecture at all. it’s a technical limitation of spark’s IO model, dressed up in a marketing department’s best clothes and sold as best practice.
a brief history of reading big files quickly
what spark actually is
the history is how you see through the marketing.
if you’re not familiar with spark, the short version: it’s MapReduce on steroids. i cannot recommend enough that you read the original MapReduce paper. it’s open source, it’s one of the most important papers in distributed computing, and it will give you the mental model for everything that follows. then read the spark documentation.
what spark does is construct a DAG (directed acyclic graph) of idempotent operations over files, splitting those operations into parallelizable tasks and sending them across nodes, which when executed, have their results read back. that’s it. the magic is in how efficiently it does this, not in what it is.
the way you commonly interact with these distributed files is either by declaring operations directly on a “dataframe”, or through SparkSQL, which is a SQL parser, both allowing workflows to be expressed over distributed data from some source. it sounds fancy but the underlying ideas have existed for a long time.
parquet and the art of skipping things
apache parquet is a columnar storage format and the de-facto standard for storing masses of data directly on disk for a few good reasons.
data is organized into row groups, each containing column chunks, each containing compressed pages, with a footer that stores schema and column-level statistics (min, max, null count). this structure enables three operations that make analytical workloads fast.
columnar pruning: a query touching 4 of 100 columns reads roughly 4% of the data. csv/json or any other format which requires you to make row-wise scans requires 100%.
predicate pushdown: the engine reads min/max statistics from column chunk footers and skips entire row groups that provably cannot contain matching rows. the data never leaves disk. a great example of this is using a sortable identifier when you know what you’re looking for. you’re accessing every physical file and raising a question per scan, naturally, more expensive than being able to leverage look-ups against a central index you can depend on.
partition pruning: data is physically organized into directory partitions (e.g.
year=2024/month=03/). so queries containing partition filters can skip entire directories.
so, idempotent operations can avoid reading tables by reading metadata, eliminating what they can, and parallelizing the remainder across executor tasks. this is why parquet became the standard for OLAP (which are broadly map-reduce like operations instead of a robust index), it turns sequential full-table scans into selective, parallel, columnar reads.
parquet in a data lake
the easiest way to think of a data lake is as a place where you store massive amounts of structured data on cheap hyperscaling object storage. your google photos library is one — billions of photos, but you can find yours because everything is organised by date, location, and metadata. a metadata data lake works the very same way. parquet files partitioned by sensible keys, queryable through engines like trino (athena under the hood), or spark, which can do a fan-out operation making use of the file format’s features.
now, storing petabytes of data in raw parquet files has real problems. no ACID transactions — failed writes left partial, corrupt files. no concurrent write safety — multiple writers silently clobbered each other. listing millions of files on S3 was painfully slow. no updates, no deletes — parquet is immutable. it was on you to build or buy reliable indexing on top. the files were dumb and the metadata was scattered.
all of these engines use the same fundamental pattern underneath: scatter work across nodes, process in parallel, shuffle, aggregate. the concept didn’t change. the ergonomics did.
eventually, storage got so cheap that the whole pattern flipped — engineers stopped transforming data before they stored it and started storing everything first, transforming later.
out of the furnace ELT was born! a moment where we collectively decided it was fine to just dump everything into S3 and figure it out later. i often think this is quietly the reason the medallion architecture feels so natural to people who never stop to ask why it exists.
the table format solution
the “lake” part in this machinery is aspirational though. without a metadata layer the data and the information describing it are decoupled — you’re dependent on external catalogs managing either lexical ordering, or Z-ordering for data locality, because the cost of reshuffling is prohibitive if you ever need to change the structure. hence your ‘source of truth’ is a fractured ontology across systems that can’t talk to each other.
your data lake is microservices
the authors of delta lake and apache iceberg sought to knit this back together by adding a metadata layer on top of parquet. delta lake stores a _delta_log directory of sequential JSON commit files. each commit records atomic actions. about every 10 commits, an encoded checkpoint aggregates the cumulative state, so readers don’t have to replay the entire history. this process is broadly known as compaction.
since the transaction log contains exact file paths, instead of calling listFrom() on S3 across millions of files across many segmented prefixes (expensive, bad), delta reads the log to know exactly which files constitute the table (cheap, good).
notably, delta lake 2.3+ implemented deletion vectors for merge-on-read: instead of rewriting entire parquet files for deletes and updates, delta creates a roaring bitmap, which basically just lets delta mark deleted row positions for cleanup so readers can filter at read time.
what this unlocks is physical compaction can happen later, via the OPTIMIZE command, for roughly 2-10x improvement on DELETE operations, at the cost of some read overhead later down the line.
iceberg takes a slightly different approach, but ultimately, both formats converge on the same goal: making parquet files behave like database tables.
this was a genuine leap forward. delta lake became the de-facto standard for Databricks tables for their ‘offline’ storage universe.
but what came next took two steps back…
so what’s so special about bronze?
the driver problem
the spark documentation is explicit about one fundamental constraint: “data cannot be shared across different spark applications (instances of SparkContext) without writing it to an external storage system.” spark is a pull-based system. it reads data from where it already exists — S3, ADLS, HDFS, kafka. external applications cannot push data into a running spark cluster the way you INSERT into postgres. there is no persistent spark service accepting writes.
to understand why, look at how spark actually runs:

each spark application has a driver, a single JVM process that creates a SparkContext, which negotiates the resources it wants with the cluster manager, and coordinates all execution. it breaks down your proposed operations into stages of parallelizable tasks, ships them to executors on worker nodes, and collects results back.
this means to get data into spark, you had two options. either you attached directly to the driver (running in the same JVM, same failure domain, same software versions), or you used a framework like apache livy, a REST service managing spark contexts via HTTP/JSON that never graduated from the apache incubator.
so in practice, the universal pattern became:
- source system →
- ingestion tool (kafka, CDC, checkpoints stored in S3 using RocksDB) →
- object storage (S3/ADLS) →
- Spark reads and processes.
you submit jobs, and those jobs pull data in. there is no way for external applications to push data directly into a running spark cluster, and in the case of spark streaming it’s just a continuously running job performing pulls in microbatches.
the merge bottleneck
with this in mind, here’s the piece that databricks’s marketing material conspicuously omits.
delta lake uses optimistic concurrency control. when you run a MERGE INTO, the process goes: read the latest table version, scan target data, join source with target, determine matched/unmatched rows, write new parquet files with updates applied, then attempt an atomic commit to the transaction log.
if another transaction modified the same files between your read and your commit, it fails. on S3, only one writer can commit at a time — implementations like delta-rs use DynamoDB for locking, serializing all writers through a single bottleneck. without deletion vectors, MERGE rewrites entire parquet files containing any matched rows — even unchanged rows get copied. this is significant write amplification, and because it’s atomic, contention over any one file blocks the entire operation.
so what do you do? you batch batch baby. you collect all the data you want to upsert into a single operation, minimizing the number of files spark needs to scan and update, and you minimize the contention from concurrent writers. naturally you want to collect everything into a partition so you can perform that merge at once, because spark performs best when it’s minimizing the number of files it needs to grep and update.
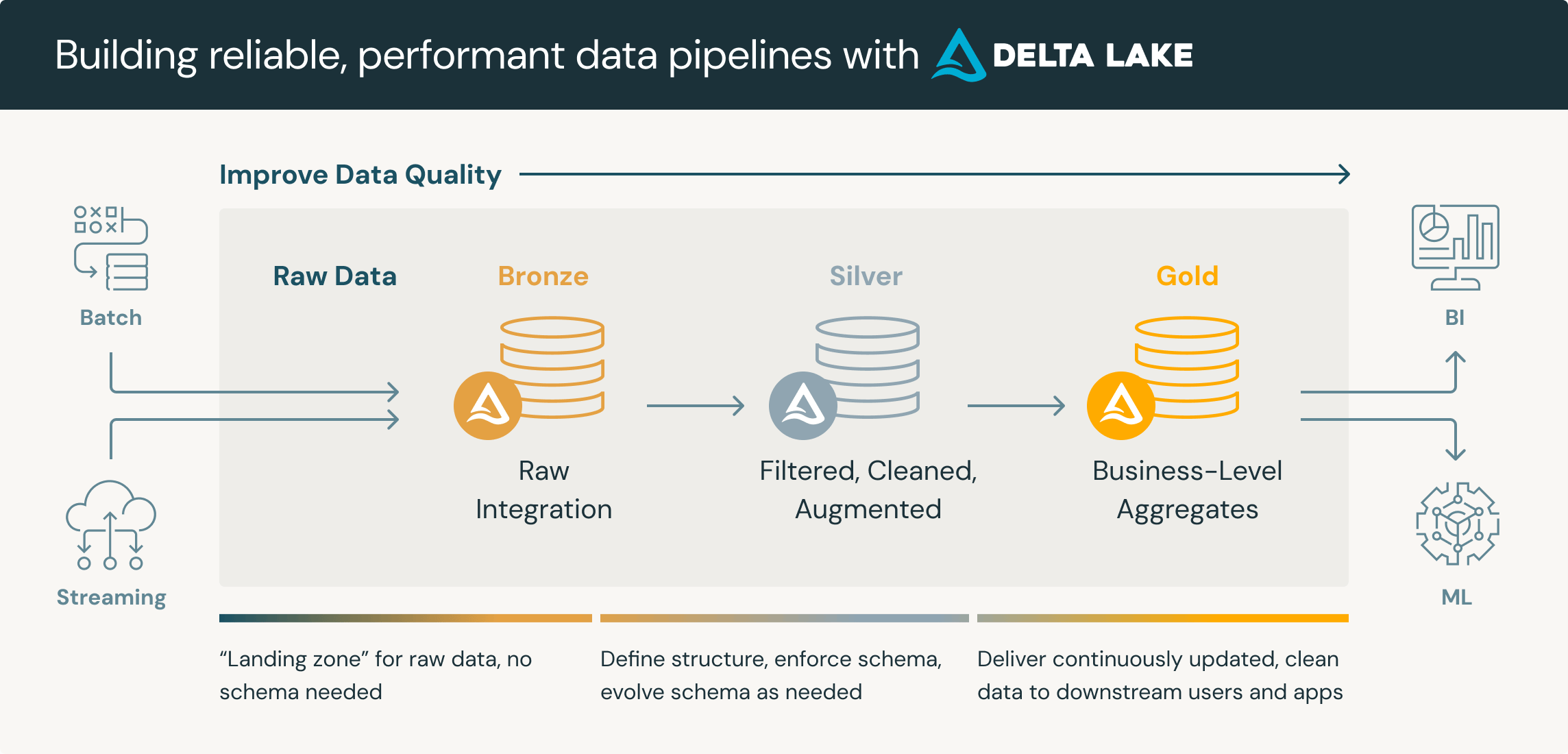
and that is exactly what the bronze layer is for.
bronze is not ’the best practice’ it’s a workaround.
bronze is advertised as “this is how you should be ingesting data into databricks because it’s the best data practice.” the docs explicitly say “databricks does not recommend writing to silver tables directly from ingestion.” they want you to land raw data into an append-only bronze table, then MERGE that data into silver in batches.
the marketing says this is about “incrementally improving data quality.” the reality is two things:
the spark IO constraints: because spark is pull-based and operates through job submissions, you need somewhere for the data to land before spark can process it. bronze is that landing zone.
the merge conflict problem: by collecting all incoming data into a single bronze append, you can perform one congruent MERGE into silver, minimizing file-level contention and write amplification.
databricks has called this the medallion architecture, not because it is the best practice for data management in principle. but because it is the best way they could find to sell the concurrency limitations of their own storage format and the constraints of spark’s execution model as a feature. they swept it under the rug and stuck a shiny label on it.
riot games has a name for this kind of thing. they call it MacGyver tech debt , two conflicting systems duct-taped together at their interface points and shipped as a feature. the medallion architecture is exactly that. and every company that adopts it is building their data platform on top of limitations that are already being solved. causing a velcro vendor lock-in feeding a global tech-rot destined to eventually pull apart. the community will never question it. they never do.
and that’s just what a sales team needs.
spark connect and the death of the job submission
spark connect was introduced in spark 3.4 (GA april 2023) as a decoupled client-server architecture. remember the driver problem — client code had to run in the same JVM as the spark driver, using Py4J for python bridging, with identical software versions and shared failure domains. if your client crashed, the driver crashed. if the driver crashed, everything crashed.
spark connect replaces all of that with a clean client-server protocol:
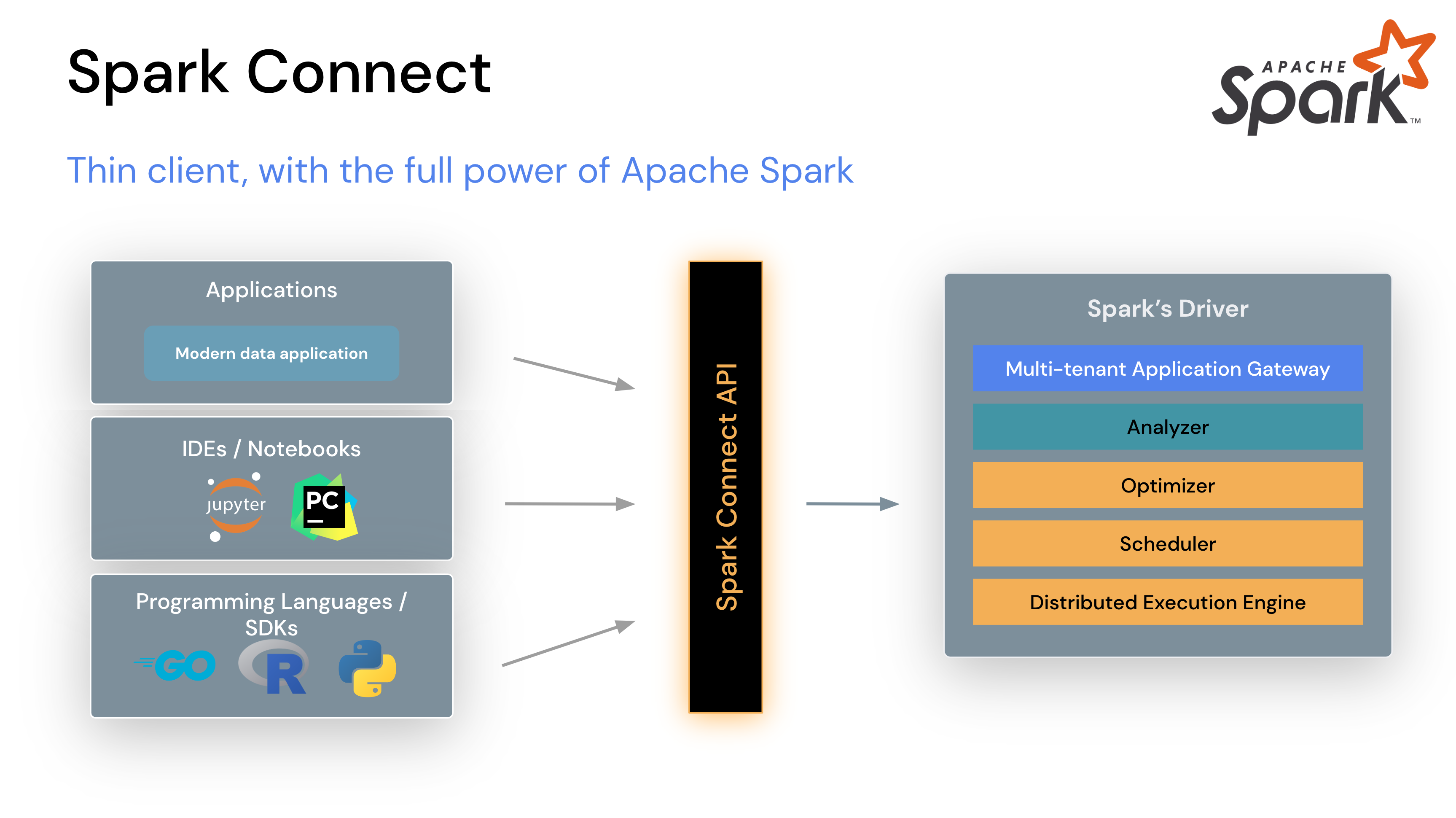
the client-server split works via gRPC over HTTP/2:
- a thin client library constructs unresolved logical plans from dataframe operations
- plans are encoded as protocol buffers (language-neutral, platform-neutral)
- encoded plans are sent to the spark connect endpoint via gRPC (default port 15002)
- the server resolves plans into spark’s internal logical operators and executes through catalyst
- results are streamed back as apache arrow-encoded row batches over gRPC
the connection string is sc://hostname:port/;token=ABC. each client gets an isolated session. client crashes don’t affect the driver or other clients. you don’t need to attach to a driver JVM. you don’t need job orchestration. you don’t need apache livy.
this is the part that matters: spark connect lets you build stateful applications that dial directly into a spark cluster on the application layer, construct and execute dataframe operations against the execution model, and validate data up front before it enters the lakehouse.
instead of:
- accept messy data from upstream
- dump it into a bronze landing zone
- hope your async pipeline catches the edge cases
- debug at 7pm when the silver MERGE fails on malformed records
- write a backfilling process
- repeat
you can:
- accept data via your application’s API
- validate schema, types, and business rules synchronously
- reject bad data at the door and tell the caller why
- push validated data directly through spark connect
- the caller handles retries on their side
this is not hypothetical. i move about a terabyte of data at a time into spark over gRPC using go.
creating a mess downstream is not best practice
this needs to be said plainly. the medallion architecture’s bronze layer institutionalizes accepting messy data. databricks recommends storing most bronze fields as string, VARIANT, or binary “to protect against unexpected schema changes.” they are telling you to accept garbage and sort it out later.
this is backwards.
when it comes to external data providers, there is always a negotiation of how they integrate with you. in reality — let alone with internal teams or where you control the contracts — there is almost never an excuse for having messy data landing zones. you define your schema. you document it. you enforce it at the API boundary. if the data doesn’t conform, you reject it and explain why.
the only reason you have to instrument messy data in the first place is because you’re accepting data directly into your landing zone, probably using databricks autoloader. the only reason you do that is because people buy into the medallion architecture. this is circular reasoning that never addresses the core problem:
don’t for the love of god ingest unstructured messy data at all. have conversations with your providers to set social contracts and programming standards.
there’s a secondary benefit here too: by removing your dependency on the medallion architecture you remove a big part of your vendor lock-in. the only thing left is autoloader keeps you trapped on databricks.
you don’t need to be. your data is parquet on object storage. any engine can read it. and honestly? implementing autoloader yourself is not a hard problem to solve.
the great irony: databricks already uses spark connect
here’s something that most databricks users don’t realize. when you run a notebook on a databricks cluster, you are already using spark connect. the notebooks are spark connect clients talking to the spark driver via the same gRPC protocol. you only have to look at your spark jobs running on a databricks cluster to see it.
in fact, you can skip the notebooks entirely and hit the spark cluster directly with a spark connect client. here’s what that looks like:
spark, err := (&scsql.SparkSessionBuilder{}).
Remote("sc://your-workspace.cloud.databricks.com:443/;" +
"token=YOUR_OAUTH_TOKEN;" +
"x-databricks-cluster-id=YOUR_CLUSTER_ID").
Build(context.Background())
if err != nil {
log.Fatal(err)
}
defer spark.Stop()
// query unity catalog directly — no notebooks, no jobs, no orchestration
df, err := spark.Sql(ctx, "SELECT * FROM `my-catalog`.default.files")
df.Show(ctx, 100, false)
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.remote("sc://your-workspace.cloud.databricks.com:443/;"
"token=YOUR_OAUTH_TOKEN;"
"x-databricks-cluster-id=YOUR_CLUSTER_ID") \
.getOrCreate()
# query unity catalog directly — no notebooks, no jobs, no orchestration
df = spark.sql("SELECT * FROM `my-catalog`.default.files")
df.show(100, truncate=False)
val spark = SparkSession.builder()
.remote("sc://your-workspace.cloud.databricks.com:443/;" +
"token=YOUR_OAUTH_TOKEN;" +
"x-databricks-cluster-id=YOUR_CLUSTER_ID")
.getOrCreate()
// query unity catalog directly — no notebooks, no jobs, no orchestration
val df = spark.sql("SELECT * FROM `my-catalog`.default.files")
df.show(100, truncate = false)
that’s it. you’re talking to spark. no notebooks, no terraform modules for git integration, no orchestration platform. just a gRPC connection to a cluster.
and yet databricks markets databricks connect as if it’s their own invention. they have taken an open source protocol — one built by the apache spark community — and branded it as a proprietary product. their documentation says “spark connect is an open-source gRPC-based protocol within apache spark. databricks connect is an extension of spark connect.” the word “extension” is doing a lot of heavy lifting there.
what databricks connect actually does is wrap the standard spark connect gRPC call with their OAuth2 M2M authentication flow. that’s it. you perform the OAuth ceremony to get a token, pass it in the gRPC header, and the rest is standard apache spark connect.
i proved this by building databricks-connect-go, a go library that connects to databricks clusters using the standard apache spark connect protocol with OAuth2 authentication. no databricks SDK required:
// this is all "databricks connect" really is.
// perform the oauth2 ceremony yourself, pass the token as a gRPC credential.
tokenSource := oauth2.StaticTokenSource(&oauth2.Token{
AccessToken: databricksOAuthToken,
TokenType: "Bearer",
})
conn, err := grpc.Dial(
"your-workspace.cloud.databricks.com:443",
grpc.WithPerRPCCredentials(oauth.TokenSource{TokenSource: tokenSource}),
grpc.WithTransportCredentials(credentials.NewTLS(&tls.Config{})),
)
that’s the entire “proprietary” databricks connect protocol. a gRPC dial with an OAuth token.
solving the problem at its root
so databricks is busy pushing the medallion architecture as best practice, showing off their flashy veneers when what’s really needed is a root canal. let’s talk about what you can actually do instead.
job debugging on databricks is where those teeth start to show cracks. you don’t get notifications when things break without setting up a bunch of infrastructure for alerting. you depend on asynchronous workflows where failures surface minutes or hours after the data landed. while you’re waiting for data to propagate from bronze to silver — which can take upwards of 10 minutes for a single 30KB file — you could have just validated everything up front. and most critically, by accepting raw unvalidated data into a bronze “landing zone,” you set a cadence where your suppliers can use that landing zone as a dumping ground — which effectively turns your data lake into a data swamp.
this is a solved problem. software developers building web applications have been peddling the same upper bound optimization for generations: validate your inputs at the boundary, reject what doesn’t conform, and give the caller a useful error so they can fix it. there is no reason data engineering should be different.
push the predicate of data validation upstream
the idea is simple. instead of accepting raw, unvalidated data into a bronze landing zone and hoping your async pipeline sorts it out, you validate at the point of entry. you tell people to buzz off for trying to write trash to your lake.
there are several approaches using spark connect. i’m going to go through the main ones.
option 1: direct dataframe ingest
the most direct approach. construct a dataframe from your validated inputs and push it straight into spark. no intermediate files, no landing zones.
// create an arrow table from validated inputs
arrowTable, err := createArrowTableFromJSON(validatedData)
if err != nil {
return fmt.Errorf("bad data: %w", err) // reject at the door
}
// push directly into spark
df, err := spark.CreateDataFrameFromArrow(ctx, arrowTable)
if err != nil {
return err // synchronous failure, caller can retry
}
// write to your target table — skip bronze entirely
err = df.Write().Format("delta").Mode("append").Save(deltaTablePath)
reading back is just as direct — spark connect streams arrow batches over gRPC:
df, err := spark.Sql(ctx, "SELECT * FROM `my-catalog`.silver.customers")
rows, err := df.Collect(ctx)
for _, row := range rows {
fmt.Printf("id=%v name=%v\n", row.Values()[0], row.Values()[1])
}
import pandas as pd
# create a dataframe from validated inputs
validated_df = spark.createDataFrame(pd.DataFrame(validated_records))
# write to your target table — skip bronze entirely
validated_df.write.format("delta").mode("append").save(delta_table_path)
reading back:
df = spark.sql("SELECT * FROM `my-catalog`.silver.customers")
for row in df.collect():
print(f"id={row['id']} name={row['name']}")
// create a dataframe from validated inputs
val validatedDf = spark.createDataFrame(validatedRecords)
// write to your target table — skip bronze entirely
validatedDf.write.format("delta").mode("append").save(deltaTablePath)
reading back:
val df = spark.sql("SELECT * FROM `my-catalog`.silver.customers")
val rows = df.collect()
rows.foreach(row => println(s"id=${row.get(0)} name=${row.get(1)}"))
option 2: spark sql
spark sql has unbounded parameterized writes and takes dataframe management off your hands entirely. if you’re talking directly to your spark cluster (not through a databricks SQL warehouse, which has a 1000 parameter limitation that doesn’t cut it for bulk ingests), you can just write SQL.
_, err := spark.Sql(ctx, `
INSERT INTO my_catalog.silver.customers
VALUES (1, 'acme corp', 'validated', current_timestamp())
`)
reading back uses spark connect’s typed schema:
schema := types.StructOf(
types.NewStructField("id", types.INTEGER),
types.NewStructField("name", types.STRING),
types.NewStructField("status", types.STRING),
)
df, _ := spark.Sql(ctx, "SELECT * FROM my_catalog.silver.customers")
rows, _ := df.Collect(ctx)
spark.sql("""
INSERT INTO my_catalog.silver.customers
VALUES (1, 'acme corp', 'validated', current_timestamp())
""")
reading back:
df = spark.sql("SELECT * FROM my_catalog.silver.customers")
df.show()
spark.sql("""
INSERT INTO my_catalog.silver.customers
VALUES (1, 'acme corp', 'validated', current_timestamp())
""")
reading back:
val df = spark.sql("SELECT * FROM my_catalog.silver.customers")
val rows = df.collect()
rows.foreach(row => println(s"id=${row.get(0)} name=${row.get(1)}"))
option 3: the databricks good boy ceremony
if you really want to do the whole medallion thing — or if you’re working around databricks SQL warehouse limitations (the 1000 parameter limit doesn’t cut it for bulk ingests) — you can validate your inputs, write them out to parquet, COPY INTO your bronze table, and then MERGE into silver. you can dump your validated inputs back out to parquet or JSON and perform the medallion ceremony to your heart’s content:
// write validated structs to parquet on S3
s3Path, err := parquetWriter.WriteStructsForIngest(ctx, ingestID, records, tableName)
// COPY INTO bronze
err = client.CopyIntoTable(ctx, s3Path, bronzeTable)
// MERGE from bronze to silver
err = client.MergeWithStruct(ctx, MyRecord{}, bronzeTable, silverTable, "id", ingestID)
it’s worth noting that the databricks Go SDK eventually caught up and started using spark connect properly under the hood (after some well-documented performance issues). it exposes results via database/sql, which means you can use any of the standard go interfaces for reading data back:
rows, err := db.QueryContext(ctx, "SELECT * FROM silver.customers")
defer rows.Close()
for rows.Next() {
var id int64
var name string
rows.Scan(&id, &name)
}
# write validated parquet to S3
df.write.format("parquet").save(s3_path)
# COPY INTO bronze
spark.sql(f"COPY INTO {bronze_table} FROM '{s3_path}' FILEFORMAT = PARQUET")
# MERGE from bronze to silver
spark.sql(f"""
MERGE INTO {silver_table} AS target
USING (SELECT * FROM {bronze_table} WHERE ingest_id = '{ingest_id}') AS source
ON target.id = source.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
// write validated parquet to S3
df.write.format("parquet").save(s3Path)
// COPY INTO bronze
spark.sql(s"COPY INTO $bronzeTable FROM '$s3Path' FILEFORMAT = PARQUET")
// MERGE from bronze to silver
spark.sql(s"""
MERGE INTO $silverTable AS target
USING (SELECT * FROM $bronzeTable WHERE ingest_id = '$ingestId') AS source
ON target.id = source.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
the point is: even in this flow, the data was validated before it touched S3. the schema was enforced by the type system. the bronze table is clean because the inputs were clean. the MERGE succeeds because there are no schema surprises.
what i do in production
if there’s one thing i need you to come away with, it’s that in my world, the data is validated long before it enters the pipeline.
i simply don’t have messy data despite spending all my time ingesting messy datasets from open source research labs that sometimes insert an ampersand in the middle of a column name, miss information they claim to have, and then encode that data in an ASCII character set Spark OOTB can’t correctly process. because i set a precedent.
the generated Go struct implements the contract, agreed on via Protobuf across teams. hold as many of them as you can fit into memory from the upstream process before sinking back out through gRPC, or fold into your backpressure if you hanker for asynchronous processing. this is generally not something you need to do if you just round robin your requests across your distributed system, as it’s unlikely a single request to contain more than 2GB of structs.
here’s a BasicTestRecord from my test suite. every record in the system spawned looks like this after go generate:
type BasicTestRecord struct {
ID int64 `db:"id" parquet:"id"`
Name string `db:"name" parquet:"name"`
Value float64 `db:"value" parquet:"value"`
IsActive bool `db:"is_active" parquet:"is_active"`
IngestID types.SortableID `db:"ingest_id" parquet:"ingest_id"`
IngestSource string `db:"ingest_source" parquet:"ingest_source"`
CreatedAt int64 `db:"created_at" parquet:"created_at,timestamp(millisecond)"`
UpdatedAt int64 `db:"updated_at" parquet:"updated_at,timestamp(millisecond)"`
}
func CreateBasicTestRecord(id int64, name string) *BasicTestRecord {
ingestID := types.NewSortableID()
now := time.Now().UnixNano() / int64(time.Millisecond)
return &BasicTestRecord{
ID: id, Name: name, Value: float64(id) * 1.5,
IsActive: id%2 == 0, IngestID: ingestID,
IngestSource: "api", CreatedAt: now, UpdatedAt: now,
}
}
i ensure structs carry strict parquet and database tags so there’s no ambiguity about what a record looks like. each record gets its own constructor. the type system will make sure every field gets a validation ruleset.
whatever language this is in you can build an interface using your standard toolchain for building structs, objects, or data classes without orienting yourselves around medallion.
for me, inserting validated records into the data lake is almost as succinct as an ORM:
records := []*BasicTestRecord{
CreateBasicTestRecord(1, "test1"),
CreateBasicTestRecord(2, "test2"),
CreateBasicTestRecord(3, "test3"),
}
err := InsertBasicTestRecords(tc, records, tableName)
reading them back:
var results []DBRecord
err := client.QueryInto(ctx, &results,
fmt.Sprintf("SELECT id, name, value FROM %s ORDER BY id", tableName))
take a moment to pause at how simple this is versus the databricks way. no autoloader configuration. no terraform modules for git integration. no job orchestration. no rescued data columns. no debugging async pipelines at 7pm. no data swamp.
this is the validate-upstream approach in practice. the go type system is the contract. if the data doesn’t decode into the struct, it’s rejected before it touches S3, let alone delta lake. the API caller gets a synchronous error. no bronze table full of garbage. no async pipeline that silently fails. no rescued data column bullshit.
the memory limitation (and why it doesn’t matter as much as you think)
is this a perfect solution? no. you cannot collect() a petabyte of data back to a driver. at that point, maybe the asynchronous workflow makes more sense for your analytical queries.
but i doubt it.
because that problem is always going to be present whenever you collect() results back to the driver. whether you use the medallion architecture or not, if you’re collecting the full result set onto your 128GB RAM driver and then trying to shuttle that to your 512MB micro instance in AWS, you have the same problem. the architecture doesn’t save you.
what does save you is streaming. in python and scala, spark connect already provides toLocalIterator() which streams rows back to the client one at a time instead of loading everything into memory. i contributed PR #152 to the official apache/spark-connect-go repository (JIRA: SPARK-52780) to bring the same capability to go.
the implementation uses go 1.23’s iter.Pull2 for pull-based iteration with back-pressure: no rows are fetched from spark over gRPC until the previous one has been consumed. no internal buffering. arrow record batches flow from spark to the client one at a time.
by treating the spark connect client as a data access object, streaming data back out becomes this succinct:
df, err := spark.Sql(ctx, "SELECT * FROM range(100)")
assert.NoError(t, err)
iter, err := df.StreamRows(ctx)
assert.NoError(t, err)
cnt := 0
for row, err := range iter {
// constant memory — rows stream one at a time
assert.NoError(t, err)
assert.NotNil(t, row)
cnt++
}
assert.Equal(t, 100, cnt)
df = spark.sql("SELECT * FROM range(100)")
for row in df.toLocalIterator():
print(row)
# constant memory — rows stream one at a time
val df = spark.sql("SELECT * FROM range(100)")
val iter = df.toLocalIterator()
while (iter.hasNext) {
val row = iter.next()
println(row)
// constant memory — rows stream one at a time
}
that’s it. constant memory, back-pressure, streaming. this means you can have your cake of validating data up front, avoiding the asynchronous pipeline debugging headaches of dirty data in your bronze workflow, going straight to dataframes you can push upstream — and eat it too.
for use cases that genuinely require distributed reads across petabytes, you write parquet files to object storage and let spark SQL handle the parallel reads — partition pruning, predicate pushdown, columnar efficiency. that’s the standard pattern, and it’s fast. faster than the gRPC limitations, actually. but you skip the medallion ceremony. and you don’t really need databricks very much at all.
the uncomfortable conclusion
databricks peddles a set of workarounds for the historical spark IO constraints and delta lake’s merge concurrency, repackaged as best practice by a company that profits directly from the additional storage and compute those workarounds require. the databricks way is just sloppy engineering.
the bronze layer exists because spark couldn’t accept data directly. spark connect fixes that.
the append-then-merge pattern exists because concurrent MERGE operations conflict at the file level. validation upstream eliminates the need for bulk merges against messy data.
the three-layer pattern exists because databricks needed a narrative to sell their orchestration platform, their autoloader, their notebooks, and their delta live tables. without the medallion architecture, the pitch is harder: “our distributed compute engine has IO limitations that require additional infrastructure to work around.” that doesn’t fit on a slide.
the spark IO constraints were the barrier to doing validation up front. that barrier is gone. spark connect is open. the protocol is gRPC with protocol buffers. the serialization is apache arrow. you can connect to any spark connect cluster — including databricks — using the standard apache protocol with OAuth2.
databricks knows this. they have to. spark connect is running under their own notebooks. the question is how long the medallion narrative survives once enough engineers figure out they can skip bronze entirely and nothing breaks. my guess is databricks will quietly de-emphasise it, the way you stop mentioning a product that aged out. no announcement. no blog post. just a slow edit of the docs and a hope that nobody notices.
they always notice.
learn spark before you learn ‘databricks’. be comfortable with the underlying ideas of OLAP systems before you learn spark.
you’ll see how much of the databricks platform is solving problems the open source community has already solved. and that the medallion architecture is not an architecture.
you can find the code at github.com/caldempsey/databricks-connect-go and the streaming PR at apache/spark-connect-go#152. the go data lake client examples in this post are from a production system processing terabytes of data daily. all of it runs against standard spark connect. none of it requires databricks, at all.